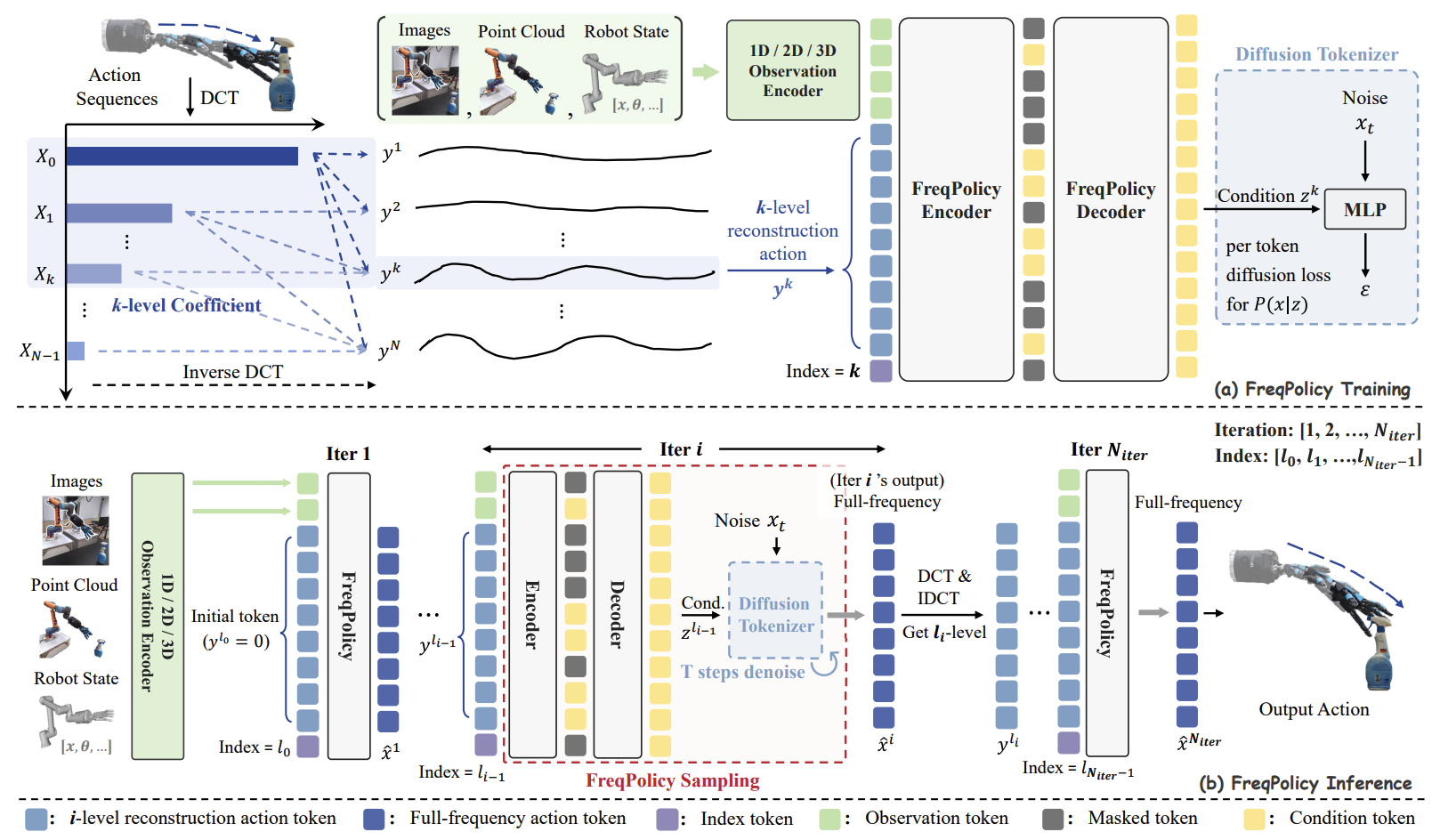
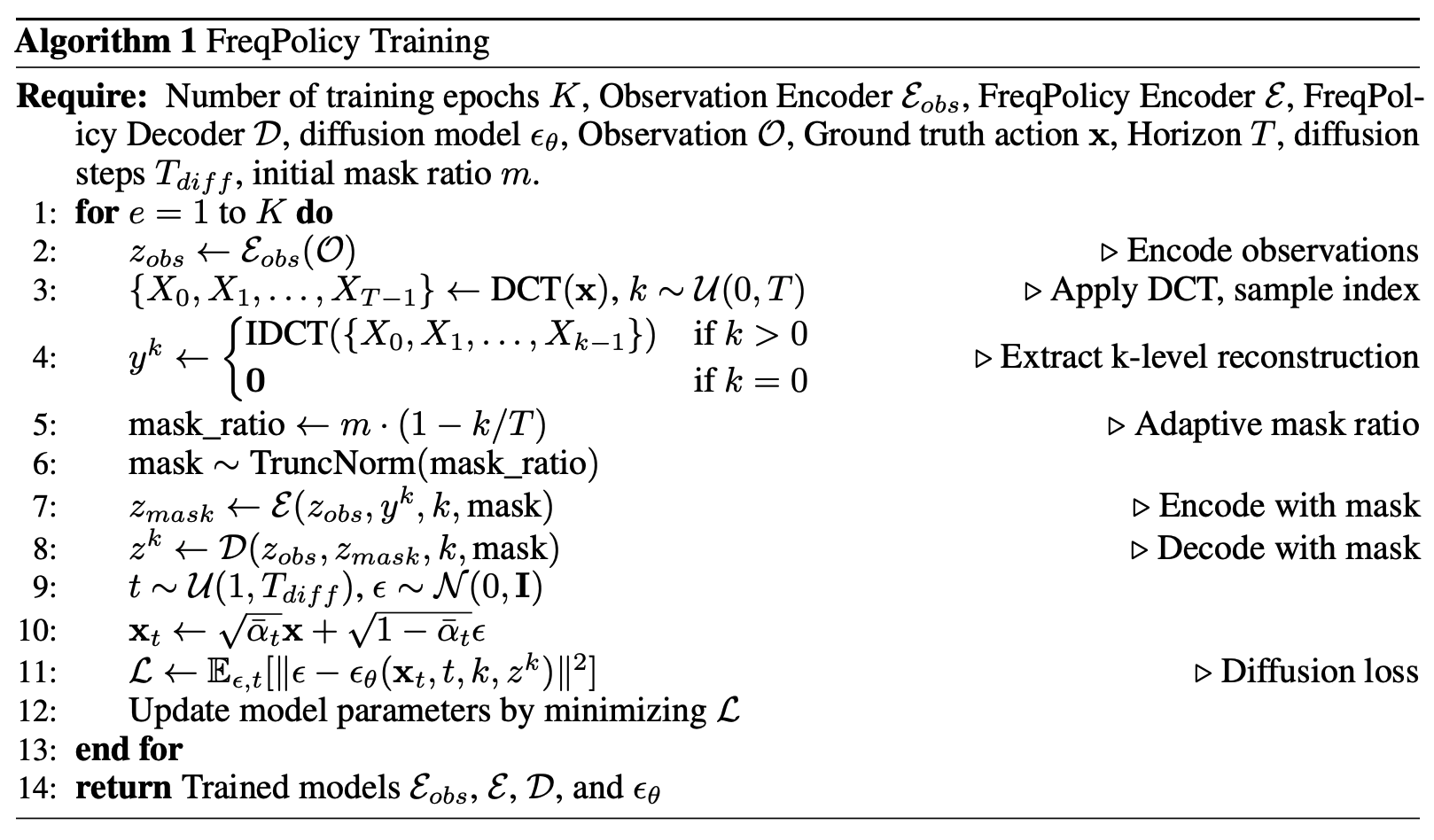
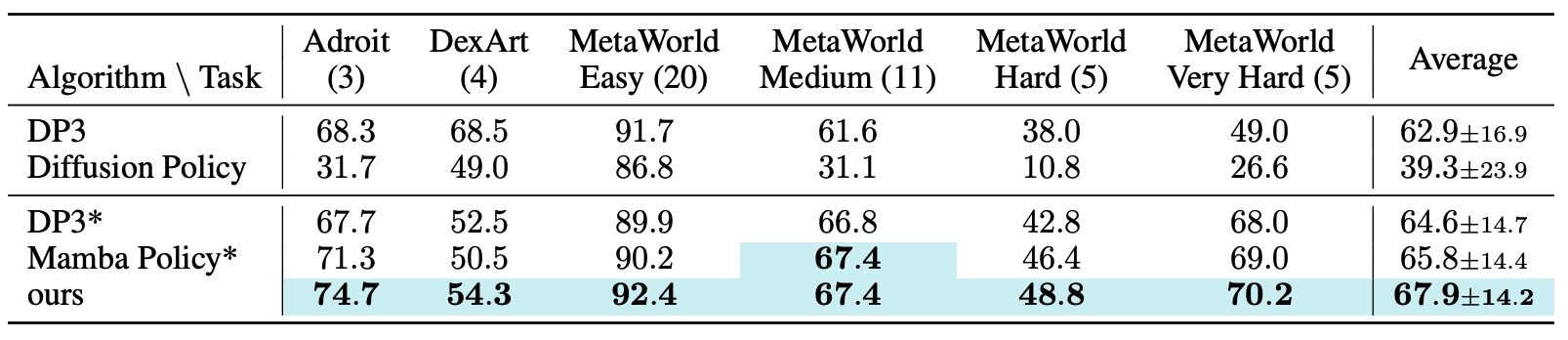
Frequency Domain Analysis
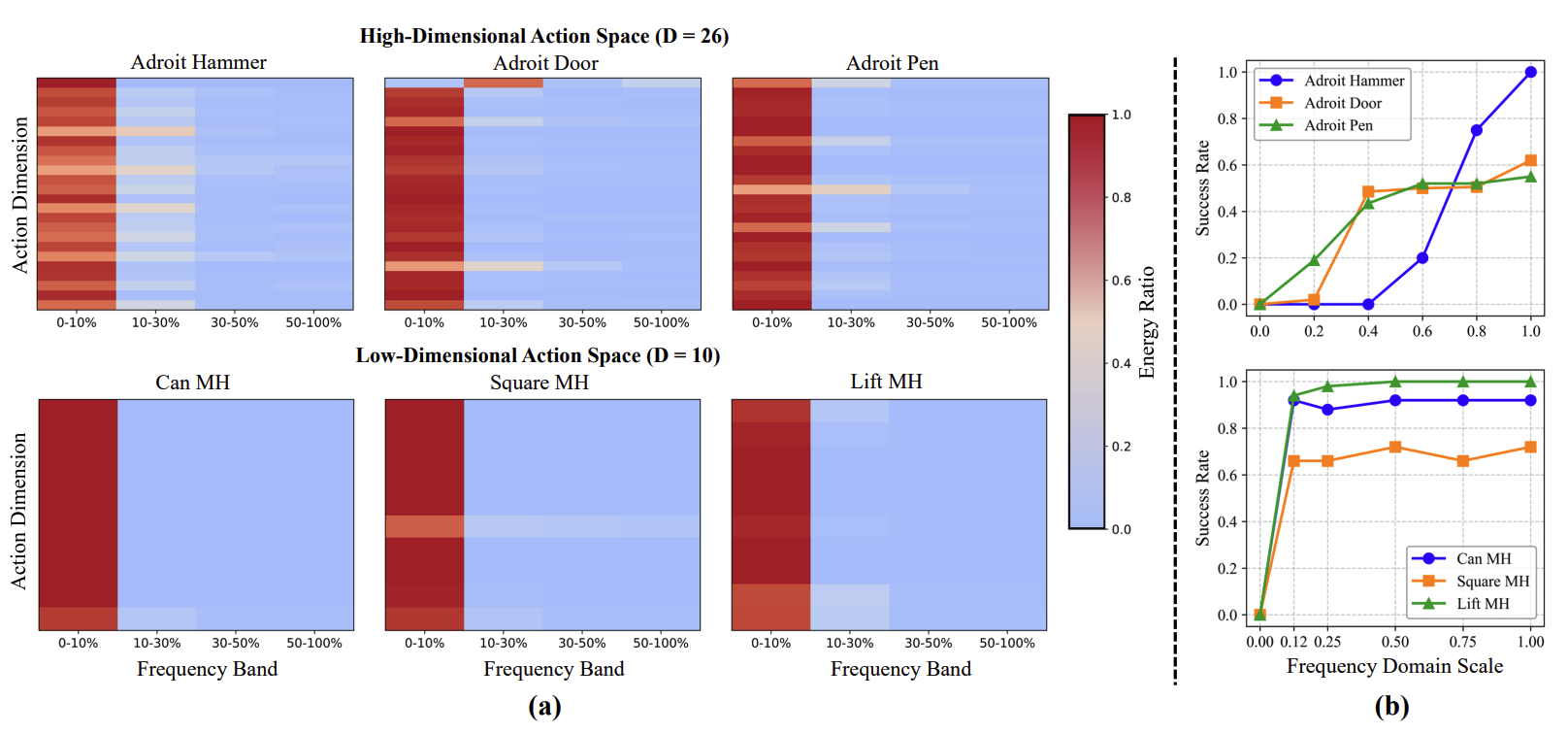
(a) Heat maps of frequency band energy across action dimensions for different tasks.The top row shows Adroit tasks with high-dimensional actions (26 dimensions), while the bottom row presents Robomimic tasks with low-dimensional actions (10 dimensions). (b) Success rate of actions reconstructed with varying frequency ratios. We reconstruct action sequences using different proportions of frequency components and evaluate their success rates on the original tasks.